Tidbits @ Kassemi
A collection of opinions, thoughts, tricks and misc. information.Saturday, June 24, 2006
Farey Sequence Python Implementation
def farey(n):
def gcd(a,b):
while b: a,b = b,a%b
return a
def simplify(a,b):
g = gcd(a,b)
return (a/g,b/g)
fs = dict()
for i in xrange(1,n+1):
for i2 in xrange(1,i+1):
if i2 < n and i != i2:
r = simplify(i2,i)
fs[float(i2)/i] = r
return [fs[k] for k in sorted(fs.keys())]
It neglects the (0,1) and (1,1) because they're obvious enough and I
end up removing them in my code anyway. Somebody out there can probably
figure out a more efficient and elegant solution, but this is pretty
quick and works just fine.
Take it easy,
James
Thursday, June 22, 2006
Killing Internet Explorer
Ah. You're in vim (unarguably the best editor of all time) designing your latest web masterpiece. You're constantly switching between your editor and the Firefox window you've got open hitting "refresh" endlessly. Your fingers are stiff, your eyes dry and scratchy, your Mountain Dew 2-Liter nearly through, and you're almost done. It's absolutely beautiful. Perfect... Your client's going to want to spend those big bucks now, and this is a great piece to add to your portfolio. You've just got to open up IE, and BAM! Your CSS float didn't display as it should have and you're going to have to spend another hour editing your design to make it work... Wouldn't it be MUCH simpler to just say screw everybody who didn't have the correct browser? The answer is yes. It would. And that's what I'm going to suggest you do.
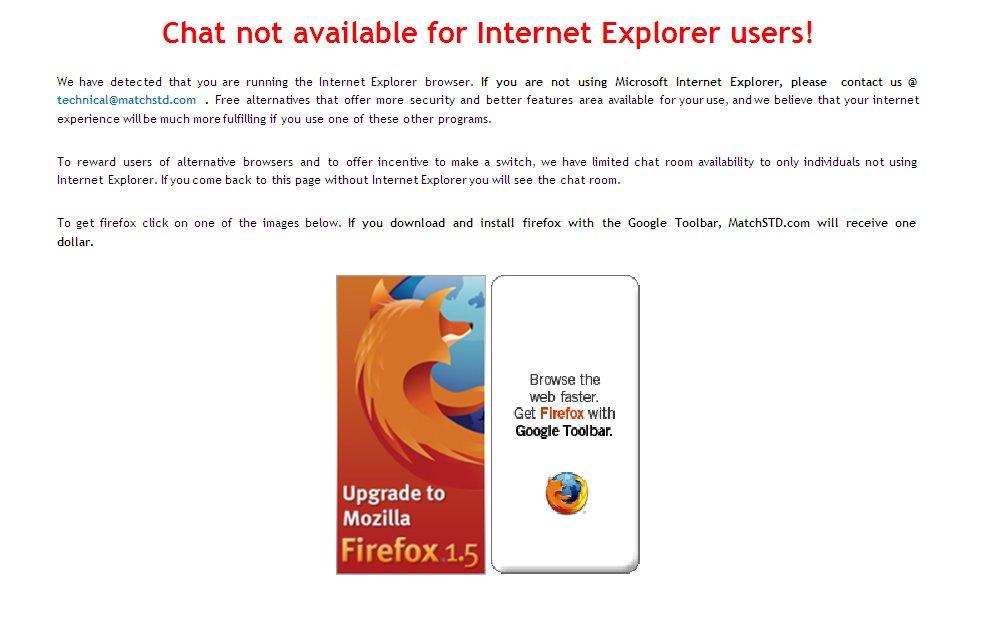
Case in point. MatchSTD.com, my latest project. Chat room access is only provided to individuals who are using a browser OTHER than Internet Explorer. If you're browsing with Internet Explorer you can get every page on the site, except the chat room:
Any other browser (Firefox, here):
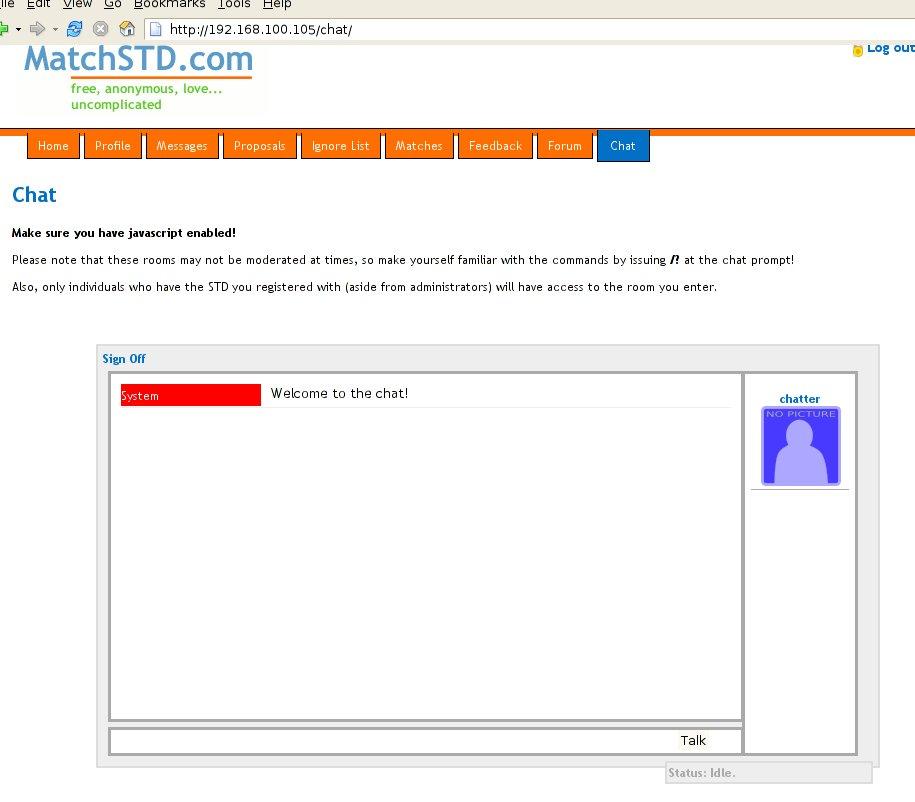
Users are informed why Internet Explorer is bad for them, and then are forced to download and use another browser if they want access to the page. It's worked well so far. The majority of users will either download install and launch a new browser, or simply switch to an already installed Firefox and access the page. The problem with this? They'll switch right back to IE because there's no reason, except when browsing this specific site, that they'd want to use Firefox instead. A normal computer user isn't going to have concerns over spyware, viruses, print-abort-proc remote code injection vulnerabilities, and the like. They'll care whether or not they can do what they aimed to do when the logged on. So why is IE not threatened by Firefox? Because we're supporting them fully. So how do we go about doing this?
- Examine your site by feature
Take a look at your site. List every specific, independent feature that you've programmed. Find a feature that's useful, fun, and not necessary for site function.
- Block Internet Explorer User-Agent Headers Access
If the user agent contains MSIE. Stop it.
You're thinking, "But James, that's really easy to spoof. I change it all the time to try to access IE-only sites!" And you are absolutely right. We're not attempting to convert users who have demonstrated such motivation, we're trying to convert the masses... And let's face it, the majority of the audience for most sites will follow the instructions that are in front of them because no desire to research instructions on something they don't even know how to google for.
The most important thing about this is that you're not blocking users from your site. You are just visibly making their internet experience more pleasurable, as they will do for you by using another browser. Make sure you provide different links for getting firefox. Try spreadfirefox.com for images and ideas. Join their affiliate program and watch your conversions grow :)
- Let others know
If other webmasters begin using this technique, users will be less inclined to switch back to Internet Explorer after they're done on your page. And it doesn't take the participation of a big site! A typical user will visit hundreds (perhaps thousands) of pages while browsing the internet. If a larger number of sites that offer Non-IE only content in relation to the number of sites that block users not using IE exist on the internet, users will be forced to switch from Firefox to Internet Explorer, generating a dislike for the latter.
If you don't have a website of your own, start making requests to other sites to block sections of content from users on Internet Explorer. Explain to them the benefits. As previously stated, It doesn't take the participation of larger sites, simply the participation of many smaller ones. Spread the word, and maybe we can start living easier without IE!
Take it easy, and thank you!
James Kassemi
james at tweekedideas dot com
james at matchstd dot com
505-991-0973
Saturday, June 17, 2006
captchas are too much fun
HTML Div parser
Event Scheduler
I was using a more complicated event scheduler, and decided I wanted to simplify it a bit, so that's the product of that. I also can't really avoid the captcha draw, so I started working on a new algorithm just in case people start breaking my old images (which hasn't happened yet, but wouldn't be all that hard). Here's a screenshot:
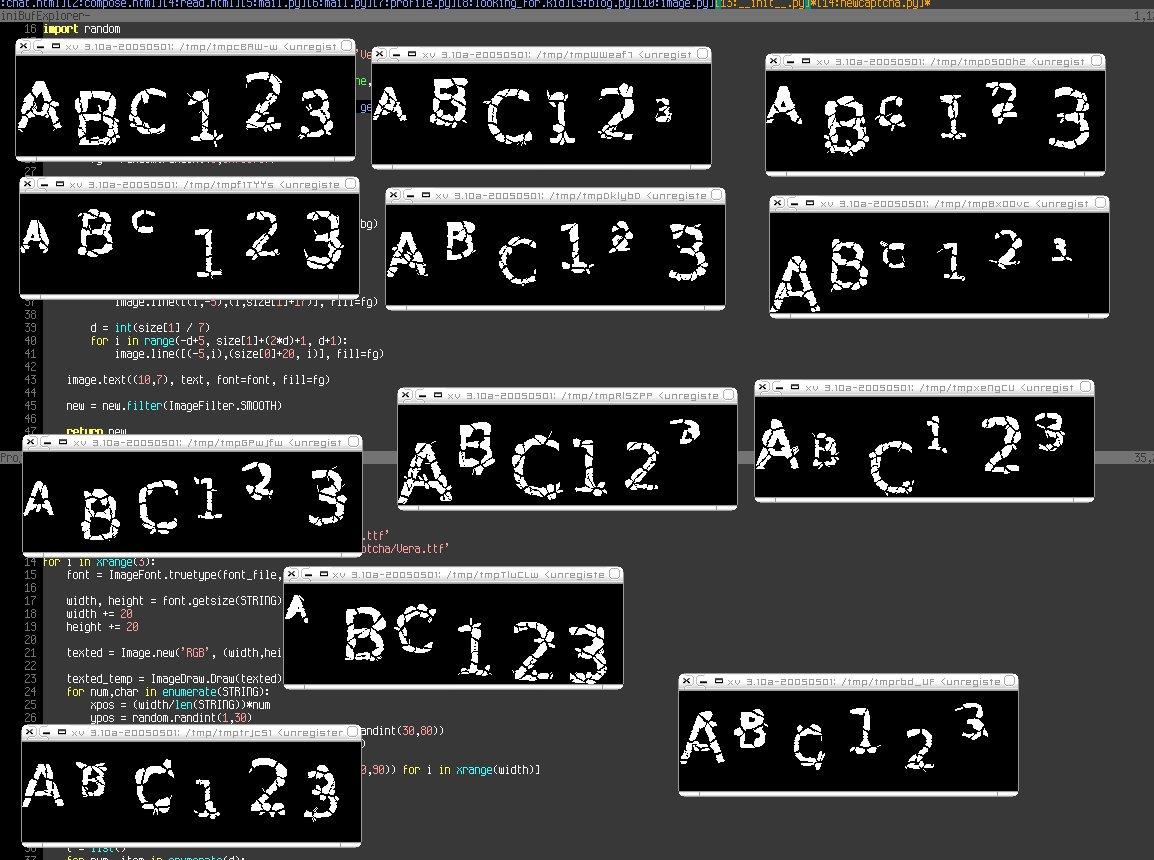
I'm using psyco because without it they're just too slow, but I've got optimization plans... I'm also going to add either some sort of disguising line, or a randomly shifted grid. I'll run some AI tests against them to see what the best idea would be. Plans to incorporate different colors also exist, but let's be honest: if a system is designed well enough, spammers won't matter to the users, and in the end, if your system can't handle the load placed on it by spammers, it shouldn't be up in the first place, so my fascination with these things is admittedly unfounded.
Have a good one!
James
Wednesday, June 07, 2006
Quck server part 2
Dump it on top of cherrypy for a quick, dirty little server for simpler requests.
'''
A BASIC server to embed inside another for simple, fast operations
Copyright (C) 2006 James Kassemi (Tweeked Ideas)
This library is free software; you can redistribute it and/or
modify it under the terms of the GNU Lesser General Public
License as published by the Free Software Foundation; either
version 2.1 of the License, or (at your option) any later version.
This library is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public
License along with this library; if not, write to the Free Software
Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
_________________________________________________________________
You'll have to bind this to a different port to handle the requests. If you
don't want to deal with apparent port differences in your code, simply
use a rewrite rule in your apache configuration, much like you do to redirect
cherrypy requests in a production environment.
Also, there are different types of request classes available here for you
to play around with... If you use the Request_Quick_CPSession class you
will be able to piggy-back the cherrypy session id generator to create
some simple sessions. I've got a database session class in cherrypy that
I also have wrapped around a request class for this, which allows manipulations
of the session from here... eh, obvious. Have fun!
'''
import socket
import thread
import threading
import Queue
import urlparse
import time
import traceback
# Straight from cherrypy
import errno
socket_errors_to_ignore = []
for _ in ("EPIPE", "ETIMEDOUT", "ECONNREFUSED", "ECONNRESET",
"EHOSTDOWN", "EHOSTUNREACH",
"WSAECONNABORTED", "WSAECONNREFUSED", "WSAECONNRESET",
"WSAENETRESET", "WSAETIMEDOUT"):
if _ in dir(errno):
socket_errors_to_ignore.append(getattr(errno, _))
socket_errors_to_ignore = dict.fromkeys(socket_errors_to_ignore).keys()
# End
WORKER_COUNT = 50
SOCKET_QUEUE = 10
TIMEOUT = 10
_SHUTDOWN = 1
STATUS_CODES = {
200: 'OK',
404: 'Not Found',
500: 'Internal Error'
}
request = threading.local()
info = threading.local()
session = threading.local()
start_thread = []
stop_thread = []
start_request = []
stop_request = []
SESSION_DATA = dict()
class Session(dict):
def __init__(self, id):
self.id = id
try:
self.update(SESSION_DATA[id])
except: pass
self['_id'] = id
def _save(self):
SESSION_DATA[self.id] = dict()
SESSION_DATA[self.id].update(self)
class Request:
''' Request processing. '''
def __init__(self, socket):
for item in start_request:
item(self)
self.socket = socket
self.rfile = self.socket.makefile("r", -1)
self.wfile = self.socket.makefile("w", -1)
self.header_temp = ''
def end_headers(self):
self.wfile.write(self.header_temp)
self.wfile.write('\r\n')
self.header_temp = ''
def send_header(self, name, value):
self.header_temp += '%s: %s\r\n' % (name, value)
def send_response(self, code):
self.header_temp = 'HTTP/1.1 %i %s\r\n' % (code, STATUS_CODES[code])
def path_process(self):
path = self.request_line.split(' ')[1]
parsed = urlparse.urlparse(path)
path = parsed[2]
args = parsed[4]
args = args.replace(';', '&')
arg_dict = dict()
try:
args = [arg_dict.update({item[0]:item[1]}) for item in [arg.split('=') for arg in args.split('&')]]
except: pass
try:
path = path[1:].split('/')
return getattr(apps[path[0]], path[1], False)(**arg_dict)
except: return False
def respond(self, code, ctype, content):
self.send_response(code)
self.send_header('Server', 'TweekedIdeas/1.0')
self.send_header('Content-Type', ctype)
self.end_headers()
for line in content:
self.wfile.write(line)
self.wfile.flush()
def process(self):
self.request_line = self.rfile.readline()
self.request_headers = dict()
while True:
header = self.rfile.readline()
if header.strip() == '': break
dl = header.find(':')
self.request_headers[header[0:dl]]=header[dl+2:].rstrip()
request.headers = self.request_headers
try:
res = self.path_process()
except Exception, e:
e2 = traceback.format_exc()
print e2
self.respond(500, 'text/plain', 'Internal Server Error\n\n%s' % e2)
return
if res:
self.respond(200, 'text/html', res)
else:
self.respond(404, 'text/html', 'Not Found')
def destroy(self):
self.socket.close()
self.wfile.close()
self.rfile.close()
for item in stop_request:
item(self)
class Request_Advanced(Request):
def path_process(self):
# Allows for generators and more complex layout.
path = self.request_line.split(' ')[1]
parsed = urlparse.urlparse(path)
path = parsed[2]
args = parsed[4]
args = args.replace(';', '&')
arg_dict = dict()
try:
args = [arg_dict.update({item[0]:item[1]}) for item in [arg.split('=') for arg in args.split('&')]]
except: arg_dict = dict()
try:
path = path[1:].split('/')
focus = app
for part in path:
focus = getattr(focus, part, False)
if not focus: return False
ret_val = focus(**arg_dict)
ret_val_type = type(ret_val)
if type(ret_val) == tuple:
from Cheetah.Template import Template
t = Template.compile(file=ret_val[0])()
data = str(t)
#data = _render(ret_val[1], ret_val[0], 'cheetah', focus)
print '...', data
return data
return ret_val
except: traceback.print_exc()
return False
class Request_Quick(Request):
def path_process(self):
global apps
path = self.request_line.split(' ')[1]
parsed = urlparse.urlparse(path)
path = parsed[2][1:]
args = parsed[4]
arg_dict = dict()
try:
args = [arg_dict.update({item[0]:item[1]}) for item in [arg.split('=') for arg in args.split('&')]]
except: arg_dict = dict()
focus = apps.get(path, False)
if not focus: return False
return focus(**arg_dict)
class Request_Quick_CPSession(Request):
def path_process(self):
global apps
c = info.cookie
try:
c.load(request.headers['Cookie'])
info.session = Session(c['session_id'].value)
except KeyError:
info.session = dict()
path = self.request_line.split(' ')[1]
parsed = urlparse.urlparse(path)
path = parsed[2][1:]
args = parsed[4]
arg_dict = dict()
try:
args = [arg_dict.update({item[0]:item[1]}) for item in [arg.split('=') for arg in args.split('&')]]
except: arg_dict = dict()
focus = apps.get(path, False)
if not focus: return False
ret = focus(**arg_dict)
info.session._save()
return ret
class Worker(threading.Thread):
''' Sits around and handles requests as they appear. '''
def __init__(self, server):
self.server = server
self.ready = False
self.go = True
threading.Thread.__init__(self)
def run(self):
for item in start_thread:
item(self)
while self.go:
self.ready = True
request = self.server.request_pool.get()
if request == _SHUTDOWN:
self.ready=False
for item in stop_thread:
item(self)
return
try:
try:
request.process()
except socket.error, e:
errno = e.args[0]
if errno not in socket_errors_to_ignore:
traceback.print_exc()
except:
traceback.print_exc()
return
finally:
request.destroy()
def stop(self):
self.go = False
class Server:
''' Grabs incoming connections and pools them. '''
def __init__(self, host='', port=8080, thread_count=10, socket_queue=5, request_class=Request):
self.host = host
self.port = port
WORKER_COUNT = thread_count
SOCKET_QUEUE = socket_queue
self.request_class = request_class
self.request_pool = Queue.Queue(-1)
self.workers = []
self.stop_flag = False
def start(self):
addr = (self.host, self.port)
import os
self.socket = socket.socket()
try: os.unlink(addr)
except: pass
try: os.chmod(addr, 0777)
except: pass
self.socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
time.sleep(.1)
self.socket.bind(addr)
self.socket.listen(SOCKET_QUEUE)
for i in xrange(WORKER_COUNT):
self.workers.append(Worker(self))
for worker in self.workers:
worker.start()
while not worker.ready:
time.sleep(.1)
while not self.stop_flag:
s, addr = self.socket.accept()
s.settimeout(TIMEOUT)
self.request_pool.put(self.request_class(s), False)
def stop(self):
self.stop_flag = True
print "Shutting down AJAX server."
for worker in self.workers:
self.request_pool.put(_SHUTDOWN)
for worker in self.workers:
worker.stop
time.sleep(.05)
while True:
try:
del self.workers[0]
except: break
print "Done"
apps = dict()
def mount(app, name):
global apps
apps[name] = app
server = None
def start(host='', port=8080, threads=10, squeue=5, catch=False):
global server
server = Server(host=host, port=port, thread_count=threads,
socket_queue=squeue, request_class=Request_Quick_CPSession)
print "AJAX server started on %s:%i." % (host, port)
thread.start_new_thread(server.start, ())
if catch:
try:
while True:
time.sleep(3)
except:
server.stop()
server.socket.close()
Monday, June 05, 2006
A very quick little http server
for system resources. As you know, I use cherrypy frequently, and it's a great
server, but for something as simple as a setInterval poll that just checks
for messages, it's not worth it to have all that extra processing involved. In
fact, it's not even necessary to have something standards compliant... That's
why I decided to write a very simple little web server that can be used within
cherrypy by binding it to another port and mounting a very small application.
The application won't be searched any more than one level, and like I said, there
isn't any support for HTTP standards... It just fires off as many pages per second that
it can (ab -n 10000 http://127.0.0.1:8080/hello/world => 2236.12 #/sec). This compares with a simple CherryPy server on my machine running approx 350 #/sec... Yeah, my machine isn't that great, but it just leads you into finding ways to optimize more than you would ever think.
import SocketServer
import urlparse
STATUS_CODES = {
200: 'OK',
404: 'Not Found',
500: 'Internal Error'}
class Handler(SocketServer.StreamRequestHandler):
header_temp = ''
def end_headers(self):
self.wfile.write(self.header_temp)
self.wfile.write('\r\n')
self.wfile.flush()
self.header_temp = ''
def send_header(self, name, value):
self.header_temp += '%s: %s\r\n' % (name, value)
def send_response(self, code):
self.header_temp = 'HTTP/1.1 %i %s\r\n' % (code, STATUS_CODES[code])
def respond(self, code, ctype, content):
self.send_response(code)
self.send_header('Server', 'TI/1.0')
self.send_header('Content-Type', ctype)
self.end_headers()
self.wfile.write(content)
def path_process(self):
path = self.request_line.split(' ')[1]
parsed = urlparse.urlparse(path)
path = parsed[2]
args = parsed[4]
args = args.replace(';', '&')
arg_dict = dict()
try:
args = [arg_dict.update({item[0]:item[1]}) for item in [arg.split('=') for arg in args.split('&')]]
except: pass
try:
path = path[1:].split('/')
return getattr(apps[path[0]], path[1], False)(**arg_dict)
except: return False
def handle(self):
self.request_line = self.rfile.readline()
try:
res = self.path_process()
except Exception, e:
self.respond(500, 'text/html', 'Internal Server Error
%s' % e)
return
if res:
self.respond(200, 'text/html', res)
else:
self.respond(404, 'text/html', 'Not Found')
class Server(SocketServer.TCPServer): pass
class ServerThreaded(SocketServer.ThreadingMixIn, SocketServer.TCPServer): pass
apps = dict()
def mount(app, name):
global apps
apps[name] = app
def start(host='', port=8080, threaded=False):
if not threaded:
server = Server((host, port), Handler)
else:
server = ServerThreaded((host, port), Handler)
server.serve_forever()
# The sample application:
class Application:
def world(self, *args, **kwargs):
# /hello/world
return 'Hey there!'
def error(self, **kwargs):
# /hello/error
a = 1/0
return 'Error!'
if __name__ == '__main__':
a = Application()
mount(a, 'hello')
start(port=5558)
As always, have fun.... And you people should start making some comments, assuming you're reading... Maybe I should get a counter up on here....
James
Archives
August 2005 September 2005 October 2005 November 2005 December 2005 January 2006 February 2006 March 2006 April 2006 June 2006 July 2006 August 2006 September 2006 October 2006 November 2006
![]()