Tidbits @ Kassemi
A collection of opinions, thoughts, tricks and misc. information.Monday, January 16, 2006
CherryPy, SQLite, and SQLObject... A freaking mess!
Okay, well, maybe not so much. Turbogears uses all of these, so why wasn't my project properly accessing the database, instead giving me a whole load of threading errors?
I was working with threading turned off without realizing it, and the second I turned the threadpool setting in Cherrypy to a non-zero value, I began getting loads of errors from SQLObject, stating that the thread that my database object was in was not the same as the one CP was using... So, where do you start? First of all, you take a look at:
http://www.cherrypy.org/wiki/SQLObjectThreadPerConnection
The solution posed works perfectly, assuming, of course, that you want to program your code specifically to use an sqlite database. The ideal solution is that instead of using the SQLiteConnection() method, we would just use our typical connectionForURI, with a simple URI. So, why does SQLObject throw up these errors, even when we're calling for a new connection with connectionForURI every time? I spent some time looking through SQLObject code, and found a little section in connectionForURI that looks like this:
It's located in the dbconnection.py file of the sqlobject source. Take a quick look, and you'll see that the first conditional checks for a cache of the connection. If it finds it, it will return the cached connection, instead of creating a new one. This works wonderfully for thread-safe databases such as mysql and postgres, but leads to problems with sqlite...
The cachedURI's variable becomes accessable via the dbconnection.TheURIOpener object, which is simply an instantiation of the connectionForURI's parent class... So, there is a very simple solution:
Place that in the list that CP starts whenever it makes a thread, and you won't have any more problems with sqlite threading and sqlobject.
Until next time,
James
I was working with threading turned off without realizing it, and the second I turned the threadpool setting in Cherrypy to a non-zero value, I began getting loads of errors from SQLObject, stating that the thread that my database object was in was not the same as the one CP was using... So, where do you start? First of all, you take a look at:
http://www.cherrypy.org/wiki/SQLObjectThreadPerConnection
The solution posed works perfectly, assuming, of course, that you want to program your code specifically to use an sqlite database. The ideal solution is that instead of using the SQLiteConnection() method, we would just use our typical connectionForURI, with a simple URI. So, why does SQLObject throw up these errors, even when we're calling for a new connection with connectionForURI every time? I spent some time looking through SQLObject code, and found a little section in connectionForURI that looks like this:
def connectionForURI(self, uri, **args):
if args:
if '?' not in uri:
uri += '?'
uri += urllib.urlencode(args)
if self.cachedURIs.has_key(uri):
return self.cachedURIs[uri]
if uri.find(':') != -1:
scheme, rest = uri.split(':', 1)
assert self.schemeBuilders.has_key(scheme), (
"No SQLObject driver exists for %s (only %s)"
% (scheme, ', '.join(self.schemeBuilders.keys())))
conn = self.schemeBuilders[scheme]().connectionFromURI(uri)
else:
# We just have a name, not a URI
assert self.instanceNames.has_key(uri), "No SQLObject driver exists under the name %s" % uri
conn = self.instanceNames[uri]
# @@: Do we care if we clobber another connection?
self.cachedURIs[uri] = conn
return conn
It's located in the dbconnection.py file of the sqlobject source. Take a quick look, and you'll see that the first conditional checks for a cache of the connection. If it finds it, it will return the cached connection, instead of creating a new one. This works wonderfully for thread-safe databases such as mysql and postgres, but leads to problems with sqlite...
The cachedURI's variable becomes accessable via the dbconnection.TheURIOpener object, which is simply an instantiation of the connectionForURI's parent class... So, there is a very simple solution:
if yourDBsURIString.startswith('sqlite'):
dbconnection.TheURIOpener.cachedURIs = {}
connection = connectionForURI(yourDBsURIString)
sqlhub.threadConnection = connection
Place that in the list that CP starts whenever it makes a thread, and you won't have any more problems with sqlite threading and sqlobject.
Until next time,
James
Sunday, January 15, 2006
CherryPy Authentication Filter
I'm in the process of debugging a CP authentication filter that makes user authentication a whole lot easier. Once it's done, I'll try to find a way to put it up... HOSTING! GIVE ME! Anyway, use is very simple:
Now, you may be wondering, isn't that very similar to multiauth? Yes. There are differences though... For one, and the biggest, is the fact that you use a database connection through sqlobject. That's a big thing for turbogears, but I'm not sure what they've got out there already. My experience with turbogears is my experience with cherrypy and sqlobject, nothing more...
Okay. I'm tired. I'll add to this later...
James
import userauth
from userauth import authorize, UserAuth
import cherrypy
import os
class Root():
@cherrypy.expose
def index(self):
return "This is always accessible by anyone."
class Members(UserAuth):
""" Unless otherwise stated (secret()), no pages under this
module will be viewable by any member outside of the
members and admins groups.
"""
_db = 'sqlite:' + os.path.abspath('filename.db')
_authorized = ['members', 'admins']
_unauthorized = '/login'
@cherrypy.expose
def index(self):
return "You're only here if you are a member!"
@authorize(['secret'], '/nowhere')
@cherrypy.expose
def secret(self):
# It would work to just make this another section all-together, but
# it could be useful...
return "Only members of secret can access this..."
cherrypy.root = Root()
cherrypy.root.members = Members()
Now, you may be wondering, isn't that very similar to multiauth? Yes. There are differences though... For one, and the biggest, is the fact that you use a database connection through sqlobject. That's a big thing for turbogears, but I'm not sure what they've got out there already. My experience with turbogears is my experience with cherrypy and sqlobject, nothing more...
Okay. I'm tired. I'll add to this later...
James
Friday, January 13, 2006
CherryPy Infinite Autoreload after Kid integration...
HA! This sucked... CherryPy v.2.1.0 and Kid 0.8. I've spent the last four hours trying to figure out why I couldn't get Kid to work properly with CherryPy... Even the simplest little examples from the website wouldn't function. Whenever I would start the Cherrypy server, it would continue to run, automatically starting itself again and again... The simple solution was to turn off autoreload by setting the server up as production:
cherrypy.config.update({'server.environment':'production'})
But not having the automatic reload on during development is a pain. I don't want to have to continue to restart my server whenever I make the tiniest change in the code... I like to see the instant results... The way I remember with PHP... Alt-F1 (Move to browser workspace), CTRL-R (reload page). So I needed to find a fix, and I started working through all of tracks to see if anything related. I came across a change to the autoreload abilities of cherrypy made by turbogears... It told me where autoreload was, and what it was called, so I went and hacked some source...
I ended up changing the cherrypy/lib/autoreload.py file in cherrypy. Replace the reloader_thread() function with this (don't say a thing about indentation. Blogger messes that up even with pre tags... So, if you found this helpful, get me some god damned hosting!):
And restart your server... Hopefully, you'll have the same luck I did, and be able to use your server in development mode again!
The problem was simply that cherrypy didn't like eggs that were stored in zip format, and OSError would be raised whenever it encountered one. The biggest change is the os.path.exists() call, which makes sure that cherrypy thinks that an egg is a directory, and it isn't, it won't call it... It seems to work for now, but again, I don't know what the side affects are, so use at your own risk...
Good day,
James
cherrypy.config.update({'server.environment':'production'})
But not having the automatic reload on during development is a pain. I don't want to have to continue to restart my server whenever I make the tiniest change in the code... I like to see the instant results... The way I remember with PHP... Alt-F1 (Move to browser workspace), CTRL-R (reload page). So I needed to find a fix, and I started working through all of tracks to see if anything related. I came across a change to the autoreload abilities of cherrypy made by turbogears... It told me where autoreload was, and what it was called, so I went and hacked some source...
I ended up changing the cherrypy/lib/autoreload.py file in cherrypy. Replace the reloader_thread() function with this (don't say a thing about indentation. Blogger messes that up even with pre tags... So, if you found this helpful, get me some god damned hosting!):
def reloader_thread():
mtimes = {}
def fileattr(m):
return getattr(m, "__file__", None)
while RUN_RELOADER:
modlist = sys.modules.values()
for filename in filter(lambda v: v, map(lambda m: getattr(m, "__file__", None), modlist)):
if filename and os.path.exists(filename):
if filename.endswith(".kid") or filename == "":
continue
if filename.endswith(".pyc"):
filename = filename[:-1]
try:
mtime = os.stat(filename).st_mtime
except OSError, e:
sys.exit(3) # force reload
if filename not in mtimes:
mtimes[filename] = mtime
continue
if mtime > mtimes[filename]:
sys.exit(3) # force reload
time.sleep(1)
And restart your server... Hopefully, you'll have the same luck I did, and be able to use your server in development mode again!
The problem was simply that cherrypy didn't like eggs that were stored in zip format, and OSError would be raised whenever it encountered one. The biggest change is the os.path.exists() call, which makes sure that cherrypy thinks that an egg is a directory, and it isn't, it won't call it... It seems to work for now, but again, I don't know what the side affects are, so use at your own risk...
Good day,
James
Thursday, January 12, 2006
SQLObject and multiple database connections (SQLite)
After writing a functional, yet somewhat limited database connection module for all my python database needs, I came across SQLObject. It sucks to find something that does what you want better than what you've got after you've put so much time into your own solution. So, SQLObject being open source, fast, clever and incredibly easy to use, I decided I'd give it a try. I also decided I'd use sqlite for my project, making things a little more modular and simple to use. So my rewrite of my ratings system began...
It took only about an hour and half to finish the new module, and it worked wonderfully in my simple tests. sqlite was probably one of the better systems I've worked with. Postgres is just too large and painful to get working properly for small projects... On top of that, sqlobject provided the access necessary to immediately port my application to postgres if I needed it. So, I fire up vim and start writing a product module, which is a general-purpose module for working with an index of products. I decided on using a separate sqlite database for that one, so I could place all my separate databases in a single directory, and back them up as necessary, etc. It was the perfect idea, until it went totally wrong :)
SQLite provides the sqlhub, which, as it states, is a hub for processing connections... Skimming the documentation, I didn't see much about it... And for good reason. Most of the time you won't be using multiple sqlite databases in the same program... So I set up each of my modules to use sqlhub.(thread|process)Connection to define the connection that they would use, thinking that the namespace would prevent any problems. Not so... Every time I'd try using both modules together I'd end up with a glaring python traceback pointing to some pysqlite internals...
So I've spent the past few hours googling around, and I've finally found a way to get this to work... I'd actually passed by the solution earlier in my hunting through __doc__'s in sqlobject, but didn't read it right... Anyway, take a look at:
help(sqlobject.dbconnection.ConnectionHub)
That's where the answer lies. It's too freaking simple :)
Just set up your modules to each use their own specific connections:
Module 1:
dbConnectionA = dbconnection.ConnectionHub()
class tableForA(SQLObject):
""" A table for module 1 """
_connection = dbConnectionA
...
dbConnectionA.threadConnection = connectionForURI(dbfile)
Module 2:
dbConnectionB = dbconnection.ConnectionHub()
class tableForB(SQLObject):
""" A table for module 2 """
_connection = dbConnectionB
...
And now you can use the modules together without any conflicting connections. I've yet to apply these to cherrpy, which I hear can be problematic due to SQLite's lack of happy threading support... That's for tomorrow...
-James
It took only about an hour and half to finish the new module, and it worked wonderfully in my simple tests. sqlite was probably one of the better systems I've worked with. Postgres is just too large and painful to get working properly for small projects... On top of that, sqlobject provided the access necessary to immediately port my application to postgres if I needed it. So, I fire up vim and start writing a product module, which is a general-purpose module for working with an index of products. I decided on using a separate sqlite database for that one, so I could place all my separate databases in a single directory, and back them up as necessary, etc. It was the perfect idea, until it went totally wrong :)
SQLite provides the sqlhub, which, as it states, is a hub for processing connections... Skimming the documentation, I didn't see much about it... And for good reason. Most of the time you won't be using multiple sqlite databases in the same program... So I set up each of my modules to use sqlhub.(thread|process)Connection to define the connection that they would use, thinking that the namespace would prevent any problems. Not so... Every time I'd try using both modules together I'd end up with a glaring python traceback pointing to some pysqlite internals...
So I've spent the past few hours googling around, and I've finally found a way to get this to work... I'd actually passed by the solution earlier in my hunting through __doc__'s in sqlobject, but didn't read it right... Anyway, take a look at:
help(sqlobject.dbconnection.ConnectionHub)
That's where the answer lies. It's too freaking simple :)
Just set up your modules to each use their own specific connections:
Module 1:
dbConnectionA = dbconnection.ConnectionHub()
class tableForA(SQLObject):
""" A table for module 1 """
_connection = dbConnectionA
...
dbConnectionA.threadConnection = connectionForURI(dbfile)
Module 2:
dbConnectionB = dbconnection.ConnectionHub()
class tableForB(SQLObject):
""" A table for module 2 """
_connection = dbConnectionB
...
And now you can use the modules together without any conflicting connections. I've yet to apply these to cherrpy, which I hear can be problematic due to SQLite's lack of happy threading support... That's for tomorrow...
-James
Wednesday, January 04, 2006
My vmware experience with slackware
Hello everyone, I've been playing around with VMware recently... A program that allows you to create virtual machines (thus VM), which are simply virtual computers on which you can run a variety of operating systems and such. The benefits such software makes to the programming world are unimaginable. VMs are used to study viruses and develop operating systems, as when something goes wrong, they can simply be deleted, and are always isolated from the system.
So I started by getting a copy of VMWorkstation, and attempting an install on my system. Of course, slackware isn't supported, and I ended up having to create a few directories in etc:
rc0.d, rc1.d, rc2.d, rc3.d, rc4.d, rc5.d, rc6.d, and rc.initd
After that, I was able to get the installation script to run, and could get the configuration script to run as well. The problem was that none of the created modules would install, and I'd always get a message along the lines of "VMware is installed, but not properly configured. Please (re-)configure VMware by running the vmware-config.pl script."
I struggled with it for a while, and then decided I had to be making a mistake. Others had reported successful installations of VMware on slackware... And then I figured it out. I haden't enabled module unloading in my kernel! So, as today was the release of linux kernel 2.6.15, I decided I'd update and enable the unloading. The new kernel was named elmers (glue bottle on my desk), and after proper configuration I rebooted.
Elmers worked just fine, and everything started up normally. Good stuff... So I made my first virtual machine, Windows XP. I develop a lot of stuff for the web, and Internet Explorer is unfortunately pretty hot with the masses, so I had to keep a machine dedicated to windows just so I could use IE... Switching between machines was tedious. I could have done a dual boot, but that takes forever, and since I often serve the pages straight from my development machine, I wouldn't have too good a time with that method. VMware was a godsend!
I set VMware to use the XP install CD, and started up the machine. The VMware boot screen came up, and then the windows install.
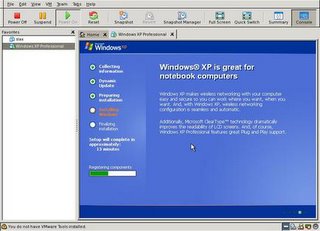
A good two hours later I had a functional Windows XP machine!

This got me to thinking... All those people I wanted to convert to linux... I now had the tool to do it! They would never have to leave behind that software they love for some reason. So I installed America Online on the virtual machine, made sure it worked, and approached my room mate...
Me: "I can put linux on your computer now."
Her: "Can I use AOL?"
Me: "Yes"
Her: "Can I play my games?"
Me: "Yes"
Her: "What about my roms?"
Me: "Yep"
Her: "And my music?"
Me: "You can do that in linux. You need to use it for everything that you can."
Her: "We'll talk later"
I've never gotten that far before. Now when I notice attacks on the wireless networks, I can just replace her VM, and I don't have to worry any more.
Oh yeah, and bow down mortals:
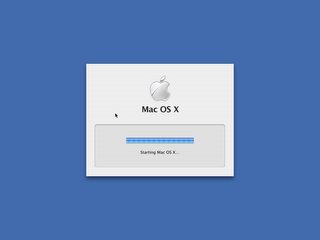
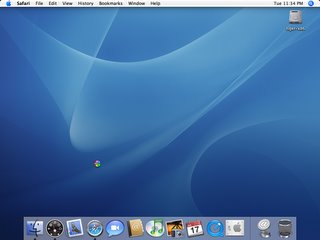
That's right. You know what it is. Way to damn slow to work with, but it's a start... Waiting for full intel support :)
-James
So I started by getting a copy of VMWorkstation, and attempting an install on my system. Of course, slackware isn't supported, and I ended up having to create a few directories in etc:
rc0.d, rc1.d, rc2.d, rc3.d, rc4.d, rc5.d, rc6.d, and rc.initd
After that, I was able to get the installation script to run, and could get the configuration script to run as well. The problem was that none of the created modules would install, and I'd always get a message along the lines of "VMware is installed, but not properly configured. Please (re-)configure VMware by running the vmware-config.pl script."
I struggled with it for a while, and then decided I had to be making a mistake. Others had reported successful installations of VMware on slackware... And then I figured it out. I haden't enabled module unloading in my kernel! So, as today was the release of linux kernel 2.6.15, I decided I'd update and enable the unloading. The new kernel was named elmers (glue bottle on my desk), and after proper configuration I rebooted.
Elmers worked just fine, and everything started up normally. Good stuff... So I made my first virtual machine, Windows XP. I develop a lot of stuff for the web, and Internet Explorer is unfortunately pretty hot with the masses, so I had to keep a machine dedicated to windows just so I could use IE... Switching between machines was tedious. I could have done a dual boot, but that takes forever, and since I often serve the pages straight from my development machine, I wouldn't have too good a time with that method. VMware was a godsend!
I set VMware to use the XP install CD, and started up the machine. The VMware boot screen came up, and then the windows install.
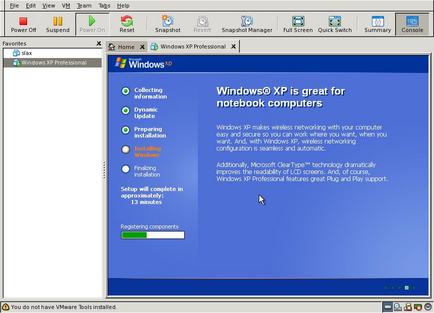
A good two hours later I had a functional Windows XP machine!

This got me to thinking... All those people I wanted to convert to linux... I now had the tool to do it! They would never have to leave behind that software they love for some reason. So I installed America Online on the virtual machine, made sure it worked, and approached my room mate...
Me: "I can put linux on your computer now."
Her: "Can I use AOL?"
Me: "Yes"
Her: "Can I play my games?"
Me: "Yes"
Her: "What about my roms?"
Me: "Yep"
Her: "And my music?"
Me: "You can do that in linux. You need to use it for everything that you can."
Her: "We'll talk later"
I've never gotten that far before. Now when I notice attacks on the wireless networks, I can just replace her VM, and I don't have to worry any more.
Oh yeah, and bow down mortals:

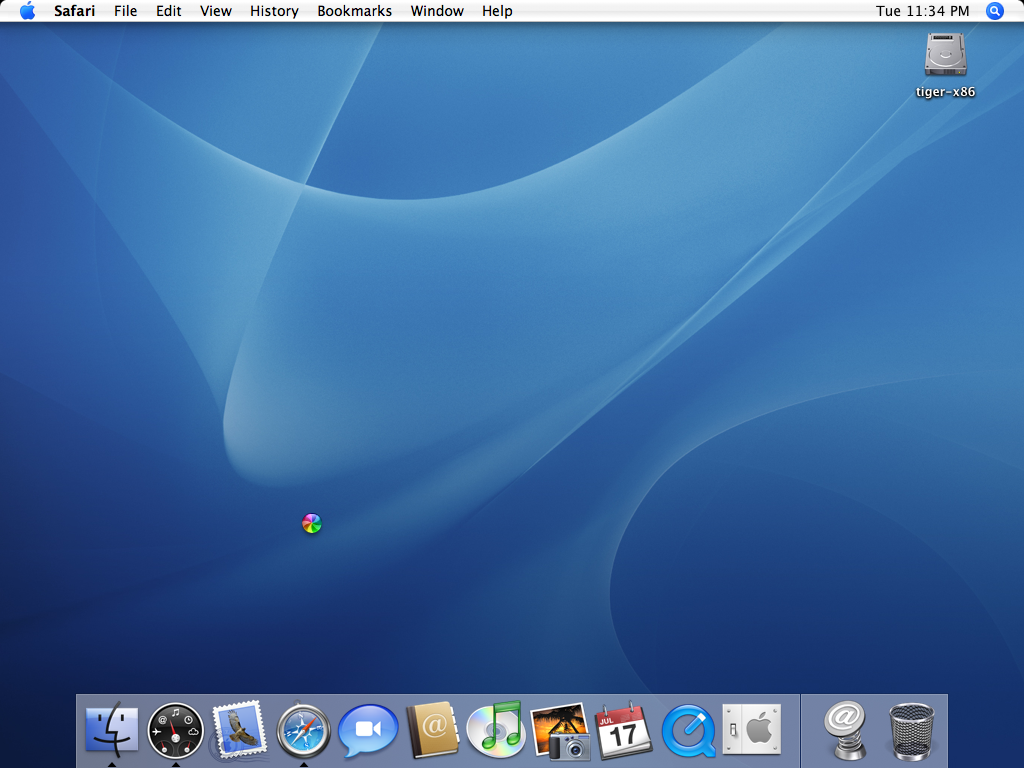
That's right. You know what it is. Way to damn slow to work with, but it's a start... Waiting for full intel support :)
-James
Archives
August 2005 September 2005 October 2005 November 2005 December 2005 January 2006 February 2006 March 2006 April 2006 June 2006 July 2006 August 2006 September 2006 October 2006 November 2006
![]()